After Thursday’s post about sports and statistics, a friend from my Williams days, Dave Ryan, raised an objection on Facebook:
There’s an unstated assumption (I think) in your analysis: that there is some intrinsic and UNALTERABLE statistical probability of getting a hit inherent in every hitter. If that is the case, then yes — a hitter whose mean is .274 that hits .330 in the first half should, reasonably, be expected to regress towards the “true” outcome of .274 in the second half; and if the hitter winds up batting .330, it’s a statistical outlier. But that ONLY applies if the underlying probability is unalterable. Which, in baseball, isn’t something you can just blithely assume. Hitters can and do get better (or worse) through coaching, experience, PEDs, or what have you. And when the mean itself is malleable, you can’t dismiss Kornheiser as just ignorant of statistical regression.
That’s a good point, and as someone who has played a lot of sports (though not much baseball– I suck at pretty much any game involving hitting a ball with a stick), I would certainly like to believe that there are real changes in the underlying distributions. I mean, it certainly feels like there are days when I’m shooting the basketball better than others, and thus there’s a higher probability of a given shot going in.
The problem, of course, is showing that scientifically, which turns out to be damnably difficult. This is related to the famous “hot hand” problem, and nobody has really managed to find any evidence that this kind of effect exists.
But the question at hand dealt with baseball, and changes in the underlying “real” batting average for a player. So let’s see if we can learn anything about this, armed with some really rudimentary statistical knowledge, and some historical statistics for players chosen not quite at random from the career batting average list.
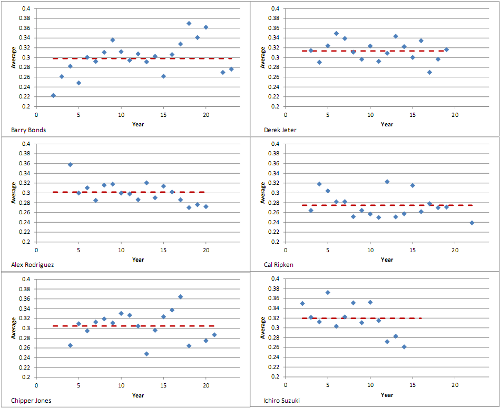
I’m sure a bunch of different sabremetric geeks have done vastly more comprehensive studies of this, but for the purposes of this blog, we’re going to settle for plural anecdotes. I went down that list and picked a half-dozen players out to look at: guys who have had fairly long careers, are generally good hitters, if not at the very top of the career average list, and are names that I recognize despite not really being a baseball fan. The six I picked were: Barry Bonds and Alex Rodriguez (because Dave mentioned drugs as a driver of changes in hitting percentages), Chipper Jones and Derek Jeter (because to the limited extent that I follow baseball, I root for the Yankees, and I have a cousin in Atlanta who’s a big Braves fan), Cal Ripken, Jr (because I was living in Maryland during the year when he single-handedly saved baseball), and Ichiro Suzuki (because he’s famously a somewhat different sort of hitter, getting lots of singles off his great speed, but not hitting much for power). That seems like enough guys to make a point of some sort, but not so many that wrestling them all through Excel makes me want to claw my eyes out.
So, the question is whether we can see changes in the underlying probability of random processes from these data, in a way that is clearly distinct from random statistical fluctuations about a single unchanging average. So here’s a graph of the batting average for each season (the blue points) compared to each player’s career average (click for a version that’s large enough to read clearly):

Those are the data we have to work with, so how would we go about determining whether there’s a real change in the underlying probability of one of these guys getting a hit from season to season? The problem, of course, is that even if there’s an absolutely fixed probability that does not change over the course of a player’s career, there will be year-to-year fluctuations just from what you would call “shot noise” in electrical engineering or quantum optics: because a season consists of several hundred attempts to hit the ball with some probability, you will inevitably get a one-season average that bounces around a bit– if each at-bat is random, you’ll get occasional “hot” and “cold” streaks naturaly.
The bouncing around can be characterized by a standard deviation, and as I mentioned in the last post, this is roughly equal to the square root of the number of hits divided by the number of at-bats. For these guys, those values come out to be around 0.02 for any given season. The horizontal grid lines on the graph are spaced by 0.02 units, so roughly one standard deviation each.
Now, for each player, you can see a bunch of points that are more than one grid line away from the horizontal line indicating the career average, which you might be tempted to cite as evidence that there are real changes. Except that’s not how it works– really, you expect 68% of normally distributed measurements to fall within one standard deviation of the mean, so roughly one-third of the measurements ought to be outside that range just due to natural fluctuations (assuming the underlying random process fits a normal-ish distribution, which is generally a good place to start).
(This is forever fixed in my mind, by the way, because I got nailed by Bill Phillips on this point when giving a presentation on some of the data for my thesis– I put up a graph of collision rate measurements with error bars, and he objected that the theory line went through too many of the error bars. He was right– I had calculated the errors in a way that was a little too conservative– and he was also one of a very small set of people who ever would’ve raised that objection…)
So, the question isn’t whether there are any points outside the nominal uncertainty range, but whether there are too many points outside that range. You can count points on those graphs if you want, but I calculated it a little more accurately in Excel, and the fraction of single-season batting averages outside the one-standard-deviation range of the career batting average are:
- Bonds: 0.476
- Rodriguez: 0.235
- Jones: 0.412
- Jeter: 0.294
- Ripken: 0.444
- Suzuki: 0.538
If this were Mythbusters, they’d probably say that the fact that none of these are the 0.32 you would expect from a perfect normal distribution indicates that they’re way off. But, really, with the exception of Bonds and Suzuki, those are not that far off. And if you excluded Bonds’s first four years, he’d be at 0.412, in line with the others.
If you want to talk about real changes in underlying distributions from these, there are four things you might point to: Bonds’s first four years (where he seems to trend sharply upward before reaching a plateau), Bonds’s peak steroid era (the cluster of high points toward the end of his run), and the last three years for both Rodriguez and Suzuki, who have been well below their prior averages for those years. The only one of those that’s really dramatic, in a statistical sense, is Suzuki’s, as he’s been at least two standard deviations off for three years running. Bonds’s steroid years are close to that, but not out of line with previous fluctuations, and Rodriguez’s recent slump is a little more marginal.
Meanwhile, Jeter, Jones, and Ripken are indistinguishable from robots.
Another way you might try to look at it is to ask what the actual standard deviation in the average of averages is. I’ll give two numbers for each of these: the first is the standard deviation of the actual set of annual batting averages, the second is an average of the standard deviations you would expect based on shot noise in the number of hits for each of those seasons.
- Bonds: 0.036 – 0.026
- Rodriguez: 0.022 – 0.023
- Jones: 0.030 – 0.025
- Jeter: 0.021 – 0.023
- Ripken: 0.025 – 0.021
- Suzuki: 0.033 – 0.022
Again, those are pretty close to what you would expect from pure randomness. If you excluded Suzuki’s last three years, he’d drop to 0.023, and excluding Bond’s first four years would bring him down to 0.030, while knocking out the steroid years would bring him to 0.028. If there’s anything real happening, those would be the spots to look.
But it’s important to note that these are very, very small datasets as statistical samples go. Throwing out four years from Bonds’s career is better than 15% of the total data, and he’s got the longest career of any of these guys. So it’s very dicey to start talking about breaking out still smaller subsets of these. And there’s not a whole lot you can point to, in an objective mathematical sense, to suggest that any of these guys have really seen significant changes that would depart from the notion of an unchanging and innate “batting average” over the course of their whole career.
One additional thing you might look at to see if there’s change happening is to compare individual years not to a career-long total average, but some sort of cumulative average up to that point in their career (that is, total career hits divided by total career at-bats for the years prior to the one being measured). Those data look like this:

There are two things to look for here: one is whether it does a better job of matching the data generally, which might suggest that it’s tracking a slow but real change that isn’t captured by a career-long average. The other is that it might make discontinuous changes departing from a long-term trend stand out more.
Again, this is pretty equivocal. The one dramatic effect this has is to do a better job matching Bonds’s first few years (because they dominate the cumulative average during that span), but this actually makes his steroid years look slightly worse. The others don’t really change much (and really, any counting of discontinuous changes ought to ignore the first few years, where the cumulative average is pretty bad, but then you’re into the too-little-data problem again).
So, what’s the take-home from this? Well, that baseball is pretty random, at least at the really rudimentary statistical level used here. It’s very hard to rule out a model where players really have a single innate “batting average” that they keep for their whole career in favor of a model where that innate average changes over time.
The other thing to note here is that this is a valuable reminder that statistical methods demand really big datasets. Even baseball, with its interminably long season of games that drag on forever, doesn’t really produce enough statistics to have all that much confidence in the averages– these are guys with long and distinguished careers, but only two of them (Jeter and Ripken) have managed 10,000 at-bats. Even on that scale, you have an uncertainty of around 0.005 in their career-long batting average. That uncertainty is much larger for shorter spans– over 0.020 for a single season– and that means that it’s just not possible to statistically detect real changes from season to season, let alone within the course of a single season. No matter how much we might like to use those random numbers to construct narratives of change.
I’d like to see you do a linear (or quadratic) regression and see the quality of the fit. You could also group your data (expressed as a delta from each player’s career average) by age (rather than player) and see how well a regression captures any trend there.
By the time someone makes it to the major leagues, it seems to me that they ought to be playing with a good deal of consistency. In fact, consistency may be a lot of what makes someone good enough to play in the majors. There are plenty of professional baseball players who predictably hardly ever get a hit — they’re on the team for fielding or pitching skill — so the coach plans the batting lineup with that in mind. Someone less predictable is harder to plan around.
So I wonder what these graphs would look like if you could include data from when these players were still learning the game.
I saw a Bayesian analysis of baseball recently, taking into account the differences in at-bats(?).
I’d like to see you do a linear (or quadratic) regression and see the quality of the fit.
Straight-line fits to the data graphed above have smallish slopes (all negative except for Bonds, ranging from +0.0027 for Bonds to -0.0053 for Suzuki) and crappy R^2 values (A-Rod is the best at 0.43, Jones the worst at 0.001). Delete the first four data points for Bonds and you get a slope of +0.0005 with an R^2 of 0.0069.
So I wonder what these graphs would look like if you could include data from when these players were still learning the game.
Probably a lot like the start of the Bonds graph, with a distinct upward trend reaching a plateau. But I suspect you’re right that the majority of players don’t get that kind of development time early in their careers. And, of course, there’s a fairly strict selection process whereby players whose average dips too low are pushed out of the league. I’ve restricted this to guys with long careers in the interests of getting enough data to say something halfway sensible, but that necessarily means I’m looking at a fairly exceptional subset of players.
This is an insightful and interesting look, but the truth is that without looking at the sabermetric data, you’re denying yourself a look at the underlying data that has a direct causal relationship to batting average. I understand that you set out explicitly not to do this, but take a look at things like BABIP & line drive rates as they trend over a player’s career, and you may find a more clear picture of what is going on. You’re missing on the details of a player’s career that do change, explicably, that have a profound effect on the player’s batting average. (aside from their batting profiles, I don’t think its much of an argument to point out that running speed changes, reaction time changes, bat speed changes – and all these affect hitting)
My own intuition on this is that players do have a single innate batting average, but it most certainly changes with time. I suspect that by selecting Hall of Fame caliber players with long careers, that you may be seeing less of a decline… and possibly less of an ascent… than might be actually true.
I’m not a sabermetrician, but I do believe in the methods, and I don’t think you can properly represent this problem without looking at a less popular construct of stats.
I’m also not a physicist, but I assume that you never intended for this level of analysis to be anything more than a simple and quasi-fun lark to look for some general correlations.
I think there’s a real trade-off, here. Yes, there are other ways to slice up the data that might produce interesting correlations, but the more pieces you slice the dataset into, the less confidence you can have in the results. 500 at-bats is going to produce something on the short side of 200 hits, and that gets you an uncertainty in batting average at the 0.02 level. You start dividing that further into specific types of hits, you’re losing another factor of maybe 4 in the amount of data, which doubles your uncertainty. The likelihood of spurious correlations goes up as well.
Now, to some extent, you can make up for that by looking at the stats for the entire league, rather than just a handful of guys. But even there, you’re not dealing with really large numbers– there are maybe 1000 players in MLB in a given year, but the bulk of the action goes to a much smaller number, probably more like 300 guys.
If you look at the problems with reproducibility and so on currently afflicting a lot of cognitive science and medical science, I think those serve as an excellent reminder of the need to be cautious in thinking about any kind of statistical analysis. My confidence in a given result is roughly inversely proportional to the complexity of the analysis needed to tease out the effect.
I can’t criticize the attempt when my criticism boils down to “you should do more work” in this sort of example. The simple truth is you are 100% right regarding the relationship between uncertainty and the value we are trying to qualify. A player can effectively be a “.300 hitter” and we should not act surprised to see roughly 2/3 of his seasons fall between .280 and .320, with maybe one real stinker and one real strong season thrown in.
It does somewhat beg the question that being a Hall of Famer somewhat (entirely?) relies on having the health to have a long career, and the opportunity to hit for most of it in a sweet spot of a quality lineup.
I guess the only reason that I would personally stick to my guns on the idea that “hitters have an innate, but variable batting average”, is that there are physical qualities of being a hitter that are known to change. I’m not prepared to rigorously defend this position in regards to how much these factors would measure up against a ~.02 uncertainty. I mean, at some point they most certainly exceed it, but by that time a player might have been long since forced to retire or been demoted to the minors.
Regardless, after reading your thoughts on the topic, I have much less respect for the annual batting champion.
But I suspect you’re right that the majority of players don’t get that kind of development time early in their careers.
Most professional baseball players in this country get their early-career development time in the minor leagues, with some getting that time in the professional league(s) of other countries (e.g., Suzuki in Japan). Very few professional baseball players go directly to the North American major leagues. I don’t know offhand if Bonds was one of those exceptions.
There is a plausible causal reason for batting averages dropping with age, which is that reflexes tend to slow a bit with age. But I don’t think that’s a linear effect, and I’m not sure how well a linear trend would approximate the effect for late-career (age 30-40) players.
As for the effect of performance-enhancing drugs on batting averages, I would think that is a secondary effect. Basically, what the drugs supposedly do for you is cause you to hit the ball further. This affects the batting average in that some of your deep fly balls to the outfield become home runs, but some of your home runs would have been home runs anyway, and some of your deep fly balls just push the outfielder further back before he catches the ball. There are statistics that might show significant effects due to juicing, but I don’t think batting average is one of them.
There is a plausible causal reason for batting averages dropping with age, which is that reflexes tend to slow a bit with age. But I don’t think that’s a linear effect, and I’m not sure how well a linear trend would approximate the effect for late-career (age 30-40) players.
I’m not particularly attached to the idea of a linear trend for that; it’s just the easiest thing to do in Excel. I could move all the data to SigmaPlot, but I’ve already spent more time on this than I ought to.
As for the effect of performance-enhancing drugs on batting averages, I would think that is a secondary effect. Basically, what the drugs supposedly do for you is cause you to hit the ball further. This affects the batting average in that some of your deep fly balls to the outfield become home runs, but some of your home runs would have been home runs anyway, and some of your deep fly balls just push the outfielder further back before he catches the ball. There are statistics that might show significant effects due to juicing, but I don’t think batting average is one of them.
There are a lot of different stories about what PED’s do– over on Twitter, somebody’s arguing that they just make player more consistent. Other accounts suggest that the main effect is to allow faster recovery, keeping players on the field more. I’m not sure how much I believe any of those.
I went with batting average here because that’s what I talked about in the book-in-progress and in the previous post, so I wanted to be consistent. It’s also probably the offensive statistic with the lowest associated uncertainty, in that it draws from the largest dataset. A decent hitter will manage 150-ish hits per year, an outstanding power hitter might get 50 HR in a year. The statistical fluctuations will be much worse in the HR numbers, by around a factor of two.
There is another factor, which was alluded to by your correspondent: Is there evidence in any of those graphs that a player started or stopped using drugs to enhance performance around a certain year?
We may have better information about that in the near future.