Now that we’ve apparently elected Nate Silver the President of Science, this is some predictable grumbling about whether he’s been overhyped. If you’ve somehow missed the whole thing, Jennifer Ouellette offers an excellent summary of the FiveThirtyEight saga, with lots of links, but the Inigo Montoya summing up is that Silver runs a blog predicting election results, which consistently showed Barack Obama with a high probability of winning. This didn’t sit well with the pundit class, who mocked Silver in ways that made them look like a pack of ignorant yokels when Silver’s projected electoral map almost perfectly matched the final results.
This led to a lot of funny Internet shenanigans, like people chanting “MATH! MATH! MATH!” on Twitter, and IsNateSilveraWitch.com. The Internet being the Internet, though, the general adulation couldn’t last forever, so there have been a bunch of people talking about how Silver isn’t really All That, and certainly not a bag of chips as well.
first out of the gate, surprising basically no one, was Daniel Engber at Slate, who argues basically that Silver didn’t do much with his complex statistical model that you couldn’t’ve done by just averaging polls.
This is true, as far as it goes– a large number of the races Silver called correctly weren’t all that competitive to begin with, so it’s not too impressive that he got those right. And if you only look at the close races, he didn’t really pick against the poll average, and the one race where he clearly did, he missed. Of course, that’s probably not too surprising. Polls are, after all, trying to measure the exact same thing that the election will eventually predict, and statisticians have been refining the process of public opinion polling for something like a hundred years. You would hope that they would do pretty well with it by now– it’s been a long time since there was a “Dewey Defeats Truman” type debacle. Any model, even a complex one, is going to necessarily line up with the results of good public opinion polls in most cases. In physics terms, Silver’s sort of doing the relativistic version of the Newtonian physics of public polling– the two will necessarily agree the vast majority of the time, and only differ when some of the conditions take extreme values. (For extra credit, calculate the velocity Montana must’ve been moving at for Silver’s model to miss that one race by the amount it did…)
Matt Springer at the reanimated Built On Facts says similar things, and also makes the important point that Silver’s full algorithm isn’t public, making it difficult to reproduce his findings. This is also an important point– if you’re not sharing the methods you used to get your results, allowing other people to replicate them, you’re veering closer to alchemy than science.
The most interesting attempt to critique Silver’s results is from the Physics Buzz blog, which tries to argue that Silver’s very success is a problem, because the chances of all the probabilities he quotes coming out exactly right are tiny. Even though Silver gave Obama a high probability of winning each of a bunch of swing states, the chance that he would win all of them, in a very simple approximation, ought to be the product of all the individual probabilities, which is a much smaller number. So, the fact that Silver “called” every one of those states correctly is somewhat surprising.
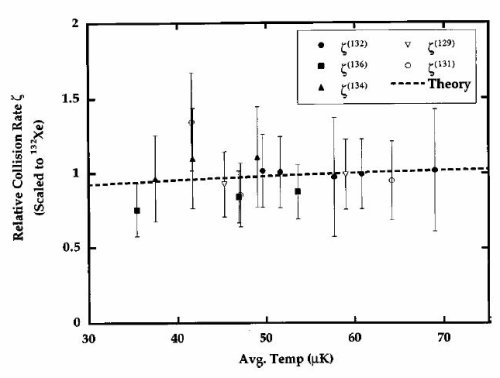
This sort of thing always reminds me of an experience I had in grad school, relating to the seemingly irrelevant graph at the top of this post (it’s the “featured image, so if you’re reading via RSS you’ll need to click through to see it). The graph shows the rate at which two metastable xenon atoms of a particular isotope colliding at a particular temperature will produce an ion as a result of the collision. This was the result of months of data collection and number crunching, and the first time I showed this at a group meeting, I was very proud of the result, and the fact that all of them are close to the theoretical prediction.
Then Bill Phillips, my advisor, went and burst my bubble by saying “I think you did the error bars wrong.” In the original figure, the error bars on the points were slightly bigger than in this one, and stretched over the theory line for every single point. As Bill pointed out, though, a proper uncertainty estimate would be expected to miss a few times– roughly one-third of the points ought to fall farther from the line than the error bars. So I had to go back and recalculate all the uncertainties, ending up with this graph, where at least a couple of points miss the line (two, rather than the 5-ish that would be the simplest estimate, but this is a small sample). I had, in fact, been too conservative in my uncertainty estimates (in technical terms, I had reported the standard deviation of a bunch of individual measurements that were grouped together to make these points, rather than the standard deviation of the mean).
This is a subtle but important point that even scientists sometimes struggle with. It’s too easy to think of “error” in a pejorative sense, and feel that “missing” a prediction here or there represents a failure of your model. But in fact, when you’re doing everything correctly, a measurement that is subject to some uncertainty has to miss the occasional point. If it’s not, you’re misrepresenting the uncertainty in your results.
Of course, that’s largely irrelevant to the Nate Silver story (though it provides a nice hook for a personal anecdote), because as people point out in the comments to that Physics Buzz post, this isn’t the only kind of uncertainty you can have. The post is correct that you would expect a low probability of correctly calling all the races if you consider them as completely independent measurements, but they’re not. The state-level results are part of a national picture, and many of the factors affecting the vote affect multiple states. silver himself was pretty up-front about this, noting repeatedly in his “swing state” reports that if Romney were to outperform his polls well enough to win, say, Wisconsin, he would most likely also win Ohio, and so on. The different state measurements are in some sense correlated, so treating them as independent events doesn’t make sense. This isn’t adequately captured by individual state probabilities, though. Which is another subtle statistical issue that even a lot of scientists struggle with.
So, anyway, what’s the takeaway from all this? Is Nate Silver a witch, or a charlatan, or what?
I think that to a large extent Silver’s personal fame is an accident– a happy one, for him. The real conflict here was a collision between willful denial of polling on the part of conservatives who really wanted Romney to be winning and media figures who really wanted the race to be close to drive their ratings and so on. He wasn’t the only one aggregating polls to get the results that he did, but being at the New York Times made him the most visible of the aggregators, which both made him the target for most of the pundit ire and the beneficiary of most of the glory when the results came in. What was really vindicated in the election was the concept of public opinion polling and poll aggregating; Silver just makes a convenient public face for that.
Does that mean his fame is undeserved? Not entirely. He was lucky to be in the right place, but he also writes clearly and engagingly about the complicated issues involved in evaluating polls and the like. He drew a big audience– something like 20% of visitors to the Times‘s political pages visited his blog— but that was largely earned by good writing. Which is not an easy thing to do.
The other question that a lot of people have been asking is what does all his complicated statistical folderol give you that just averaging polls wouldn’t? That is, isn’t his model needlessly baroque?
Yes and no. One of the things Silver’s doing, as I understand it, is trying to construct a model that will fill in where polling breaks down– that will let you predict the results of elections in states that aren’t “important” enough to get lots of public opinion surveys, by taking what polls you do have and factoring in the results of higher quality polls in demographically similar states, and that sort of thing. That’s what allowed him to even make predictions in a lot of the smaller state races– high-quality national polling firms don’t put a lot of resources into congressional races in Montana, so it’s a little harder to make predictions there.
This model wasn’t perfect, by any means, but like anything in science, it’s an interative process– having gotten the data from this election, Silver will presumably tweak the weights that he applies to various factors before trying to predict the next round of elections, and hopefully refine the model to make better predictions. In an ideal world, this sort of analysis would lead to reasonably accurate forecasts even where polling data are sparse, and that’s pretty cool if it works.
Another thing his data collection efforts can do is to help people assess the reliability of specific polls in a more systematic way. This includes things like the “house effects” that he talks about– Rasmussen polls tend to skew Republican by a couple of points, something he tries to take into account with his model. In a sense, you can invert his process, and use the corrections he applies to assess the polls themselves. Of course, since he doesn’t make all that stuff public (yet, anyway– who knows if he will eventually), this is a little tricky, but you can get some idea by comparing individual polls to his aggregate predictions.
(Of course, this is a moving target, as the pollsters are presumably doing the same sort of thing, in an effort to improve their models. I doubt Rasmussen is deliberately trying to be off by a couple of points in a Republican direction, for example, and it would be interesting to see if their bias shrinks over time as they tweak their models to get closer to the actual results.)
There’s also the question of the disconnect between the national polls and the state-level polls, a topic Silver wrote about a lot during the last few weeks. For a long time, the electoral picture looked a lot better for Obama than the national picture, in that “swing state” polls suggested he was doing better there than you would expect from polls of the nation as a whole. This was clearly a vexing question, and Silver basically bet that the state-level polling was a better indicator of the final outcome than the national polls. The success of his model may shed some light on the question of how and why that difference existed– it’ll be interesting to see what he posts about this in the next few weeks.
Finally, on a sort of meta-level, I think Silver was really useful for political culture as a whole. While the national poll numbers were always a little troubling, and the media did their best to whip up some drama, Silver’s aggregation provided a valuable corrective, in that for all the frantic horse-race chatter, the numbers barely moved. It’s a reminder that the vast majority of what you see on political blogs and cable chat shows is ultimately pretty unimportant. Thanks in part to the steadiness of the predictions of Silver and other poll aggregators, the liberal-ish crowd I follow on social media was a good deal calmer than they were back in 2008, which has benefits for everybody’s sanity.
So, in the end, like most such things, I suspect that both the initial hype and the subsequent backlash against Silver miss the mark a little. He’s lucky in addition to good, but really did provide some valuable services. And if you haven’t read his book (which he plugged on Twitter late on election night, in what might’ve been the greatest humblebrag ever), check it out, because he writes really well about a topic that in lesser hands would be crushingly dull.
“…if you’re not sharing the methods you used to get your results, allowing other people to replicate them, you’re veering closer to alchemy than science.”
That’s hyperbole. An approach doesn’t stop being science just because you don’t publish it.
It’s exaggerated a bit for rhetorical effect– this is a blog, after all– but I would stand by the basic point. A method can be scientific in spirit without being published (in that it is based on inferences from measurements and tested against empirical data), but unless it’s published and tested independently, it’s not science.
Surely one part of the fallout of Nate Silver’s fame is that other news outlets are at this moment scrambling to get their own statisticians in place. Expect Sam Wang from Princeton to start showing up on your TV soon. And others will follow. And each will employ their own methodology, and the various statistical models will compete to see who gets the best results, with better and better and earlier and earlier predictions.
Of course, “if present trends continue,” eventually it will be like ST:TOS’s “A Taste of Armageddon,” in which we all agree to abide by the results of the simulated election in order to avoid the nightmare of actual campaigns.
But the approximation is too simple. Part of the model included a systematic bias in the polls: he didn’t know how large that would be, so it was another variable. But it was (I assume) constant for all states. So if the polls were perfect other than a possible bias, then this bias could move them all up or down. if the bias is zero, he gets everything right. The more off he is, the more he gets wrong.
If you add up the probabilities of the 9 battleground states (NC,FL,IA,VA, CO,OH,NV,NH,WI) there should have been 2.47 Romney victories among them. There was one. Poisson probability with mean 2.47 and then observing one or fewer is a healthy 29%.
The sharpest simple test is really the chi-squared of the vote totals by the quoted uncertainty. For instance, in Chad’s plot above, that chi-squared would come out apparently much too small. A quick eyescan suggest’s Silver’s chi-square would be pretty good. (Remember, pollsters conventionally report MOE as 95% CL’s, so they are basically 2 sigma, not one sigma).
The weirdest case is Drew Linzer’s Votamatic. He had a model that was really heavily weighted by some kind of “fundamentals”-based Bayesian prior, and it pegged itself at Obama 332 EV and stayed pegged there even after Obama cratered at the first debate. I think Linzer’s site was less popular than some of the others in part because it wasn’t interesting to watch it not move, and in part because it seemed like a delusional prediction. But then Obama started doing better again.
In the final days, it actually started to creep down a little, but Linzer argued that 332 EV was still the most probable single value (just as Silver and Sam Wang said). And then Obama apparently got 332 EV.
The Physics Buzz post also gets this wrong, but Silver missed two senate races: Montana and North Dakota. In Montana he did in fact pick against what the polling was showing. In North Dakota the only polls he considered showed Berg ahead, but other polls he ignored (mainly because they were commissioned by Heitkamp’s campaign)–and were not ignored by Sam Wang (who predicted Heitkamp as the winner) or TPM’s Polltracker (which showed the two candidates exactly tied)–showed Heitkamp ahead.
Commenters at Physics Buzz explain exactly why the analysis in that post is incorrect. As Bob O’H above says, the events are not independent. The easiest way for a pollster to go wrong–and the way Gallup and Rasmussen actually did go wrong this cycle–is to get the likely voter model wrong. That will be a systematic rather than a random error: if you get the LV model wrong in Ohio you probably have similar issues with your LV model in Wisconsin and North Carolina. Silver tries to correct for this problem by assigning a house effect to various pollsters. I suspect this is where his error bars get too big: he doesn’t know for sure that Rasmussen has an absolute (not just a relative) Republican lean until the votes are counted.
Silver’s probabilities come from a Monte Carlo simulation. When he says that candidate A has an X% chance of winning, he means that the candidate wins in X% of his simulations.
Sam Wang’s approach is basically to assume independent probabilities in his “snapshot” calculation (not because he thinks that’s realistic, but mostly just because he has an algebraic trick that makes that case easy, so he doesn’t have to do Monte Carlo). But then he takes advantage of the ease of putting in an overall bias term to account for possible correlated systematic error and crazy black-swan events in his “prediction” calculation. Or so I understand it.
And, yeah, the big difference with Silver is that he assumed smaller variance in the second stage, though it was a fat-tailed distribution.
…Oh, yeah, and a HuffPost Pollster, they had their own model constructed by Simon Jackman, which was basically a lot like Nate Silver’s except that it assumed *even more* uncertainty from correlated errors. I think they had Romney’s win probability up around 30% or so right up to the end.
I think it’s important to remember that most people who call Silver’s methods “science” are people who use the term differently – people who use the term “political science” without irony or people who consider economics a science.
Basically, most of these people mean that he uses math. The people who take umbrage with classifying Silver’s work as science are people who actually consider science to be science (and mostly these are physicists for some reason).
Silver basically bet that the state-level polling was a better indicator of the final outcome than the national polls.
Not quite. From what I recall of his explanations, he used the state-level results as part of the input into his national estimates and vice versa. The practical effect is that, in the 2012 campaign, his national popular vote estimate tended to be a bit more favorable to Obama than the national polls by themselves would indicate, while his state estimates tended to be a bit less favorable to Obama than each state’s polls by themselves would indicate.
Relevant to the statistical anecdote in the post: a comparison of Silver’s predictions and 95% confidence intervals.
” Of course, since he doesn’t make all that stuff public (yet, anyway– who knows if he will eventually), this is a little tricky, but you can get some idea by comparing individual polls to his aggregate predictions.”
Here were the house effect numbers in June:
http://fivethirtyeight.blogs.nytimes.com/2012/06/22/calculating-house-effects-of-polling-firms/
Thanks for posting this Chad.
I wonder how many other people are going to ignore the lack of independence in the elections. Buzz Skyline got shellacked in the Physics Buzz post comments for ignoring the dependence of random variables at the level discussed in a undergrad statistics survey class*. Just the efforts of the Koch brothers alone creates significant dependence in many of the contested states.
* Seriously, it wasn’t the most rigorous class ever, I was at a podunk state school. Exercises comparing probabilities for dependent versus independent variables are instructive. As was gaining the knowledge that you have to calculate a Margin of Error – it is very definitely not a standard deviation, the two measure different types of quantitites (spread in sample populaion (sigma) vs width of confidence interval in distribution (MOE)).
Three words: Markov Random Fields.
Frankly, I don’t care if he was divining the future by looking at chicken gizzards, the bottom line is that if I had money to wager on an event, I’d like to have Nate Silver there to advise me.
I remember the original fivethirtyeight blog had methodology in mind-numbing detail. It doesn’t seem to have transferred that well to the New York Times (e.g., some links are missing) ; but please take a look at this:
http://fivethirtyeight.blogs.nytimes.com/methodology/
and please tell us what you think.
I’d add that a description of the algorithm is sufficient for it to be science; e.g., I doubt anyone programming a neural network, e.g., as they did for deciding which collision events should are interesting in CERN releases the weights for each of the neurons in the neural network. So if that was science, this too is science, as far as disclosure and repeatability of methodology is concerned.
At least his predictions settled my nerves on the night!
Newton didn’t show anyone else how he was doing calculus, did that make it any less significant? Not defending this guy or anything but damn…….
Your jealousy is showing.
The biggest thing I have a problem with is this statement in the piece “…if you’re not sharing the methods you used to get your results, allowing other people to replicate them, you’re veering closer to alchemy than science.”
Leaving aside the whole conversation that in reality I would call what Silver does “math” and not “science” I have to say it is ridiculous to call something “not science” because it is not shared,”
If I have something that is going to make me rich I’m one hell of a lot LESS likely to share it if it can be duplicated (science) than if it is unique to me (say art).
Jon, yeah actually, it did make Newton’s work less significant. That’s why we study calculus and not fluxions.
Not really apropos of anything, but Silver started out in sports statistics and after making a name for himself eventually moved into politics. Reading Silver’s numerical approach to politics ended up getting me interested in sports statistics.
With typical physicist naivety I worked a few college football metrics I though might be original, only to find that I had been soundly beaten to the punch by gamblers. Go figure!